이 문제는 '문자'로 입력을 받은 후 그 문자의 '아스키 코드 값'을 출력하는 문제입니다. C언어 방식으로 접근하면 아주 간단합니다. char type의 변수를 선언한 후에 그 변수로 '문자'로 입력을 받은 후 출력을 할때는 정수형 출력을 하게 되면 입력 받은 문자를 그대로 출력을 하는 것이 아닌 아스키 코드의 값으로 출력을 하게 됩니다. 이번 문제도 아주 간단한 문제이기 때문에 flow chart와 key point는 생략하고 넘어가도록 하겠습니다.
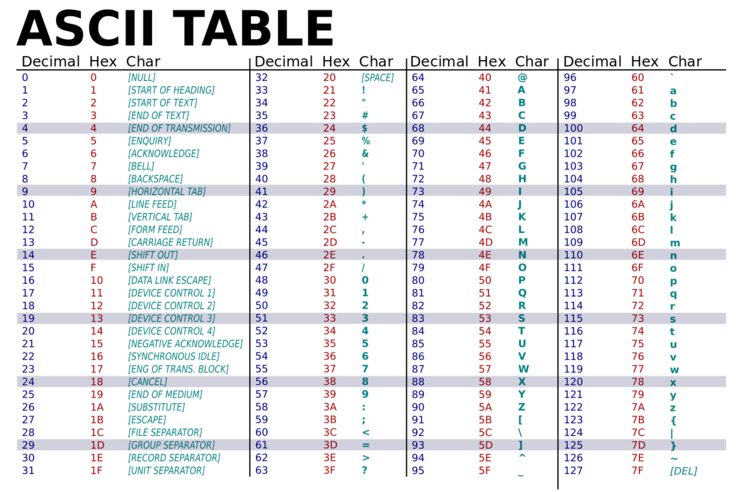
아스키 코드 표
#include <iostream>
using namespace std;
int main(){
char ch;
scanf("%c", &ch);
printf("%d\n", ch);
return 0;
}
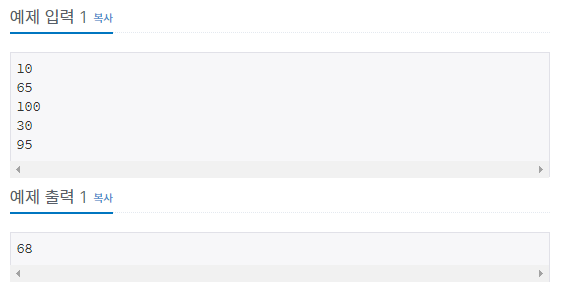
배열 문제는 대부분 간단하게 풀리는 문제가 많은 것 같습니다. 아무래도 1차원 배열이다 보니 값을 활용해 문제를 내려다 보니 한계가 있는 것 같습니다. 문제로 돌아가서 5명의 시험 점수를 평균내서 출력하는 간단한 문제입니다. 하지만 여기서 조건이 하나 추가되는데 40점 미만인 학생은 보충학습을 통해 40점을 가져갈 수 있다는 것입니다. 그리고 보충학습은 선택이 아닌 필수이므로 40점 미만 학생은 전부 40점 처리해서 풀면 됩니다. 아주 간단하죠. 출력또한 정수형으로 출력하기 때문에 자료형을 신경써줄 필요가 없습니다.
이번 문제는 간단하게 풀리기 때문에 flow chart를 생략하고 코드와 출력 결과를 첨부하고 끝내도록 하겠습니다.
#include <iostream>
using namespace std;
int main(){
int answer = 0;
for(int i = 0;i < 5;i++){
int temp;
scanf("%d", &temp);
if(temp < 40)
answer += 40; // 40점 이하는 보충학습을 통해 40점을 받게됨
else
answer += temp; // 그 이외에는 본인 점수 입력
}
answer /= 5; // 인원 수 만큼 나누기(평균)
printf("%d\n", answer);
return 0;
}
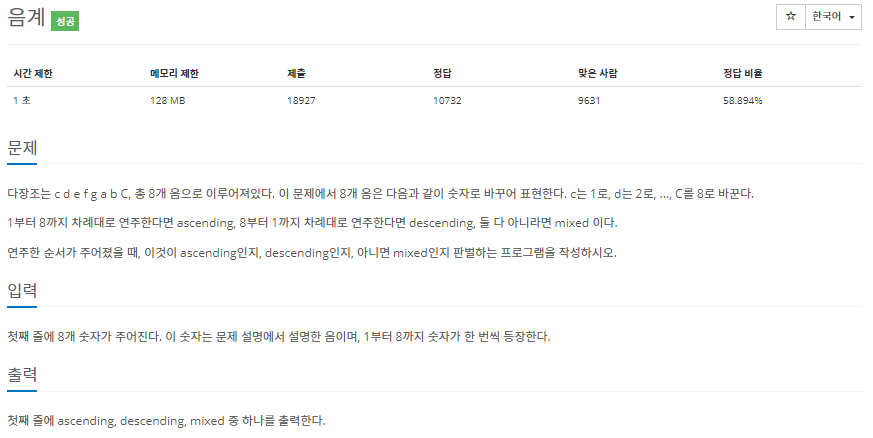
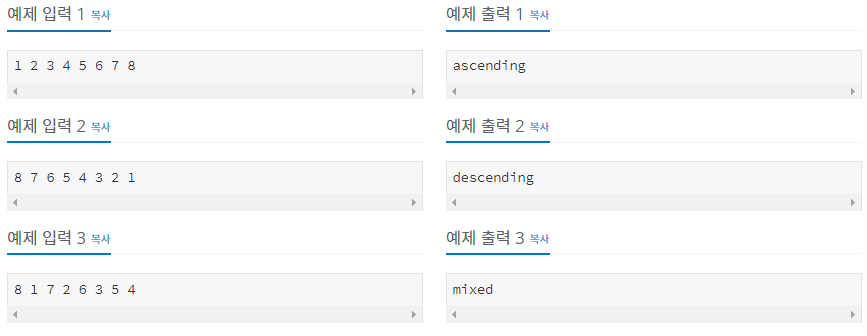
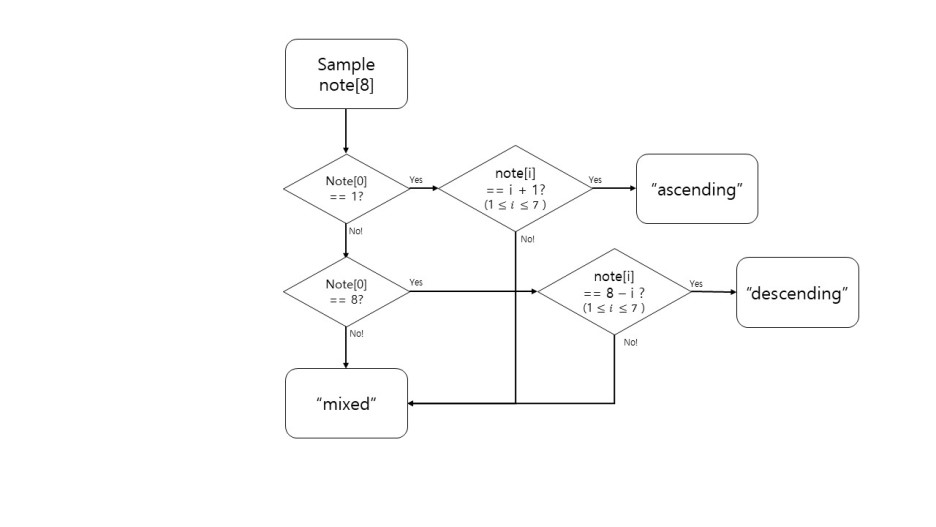
이번 문제는 다른 배열 문제보다 더 간단한 것 같습니다. 문제 자체가 1씩 감소하고 있는지 1씩 증가하고 있는지를 물어보는 것이 아닌 첫 번째 판단 조건을 주었습니다. 가장 앞자리에 오는 음계가 1인지 8인지를 먼저 판단한다면 대부분의 케이스가 먼저 걸러질 것이라 예상됩니다. 그러고 나서 1과 8인 경우에서 다음 음계가 순차적으로 왔는지 판단하고 만약 순차적이지 않다면 그 부분에서 탐색을 종료하고 "mixed"라고 출력을 하면 됩니다. 처음 문제를 접근했던 방식은 8개의 배열을 모두 탐색하면서 인접한 배열의 원소의 차를 더해가지고 판별하는 방식으로 접근했었습니다.
예를 들어 첫 번째 예제인 "1 2 3 4 5 6 7 8"일 경우 배열을 탐색하면서 1과 2의 차는 -1이고, 다음 원소 2와 3의 차는 -1이므로 더 해나가다 보면 인접 배열의 차의 합은 -7이게 됩니다. 반대로 "8 7 6 5 4 3 2 1"일 경우에는 7이 나올 것입니다. 그 외의 경우는 전부 "mixed"라고 판단하도록 했습니다. 이렇게 할 경우 현재 배열의 크기가 8이기 때문에 탐색하는데 얼마 안 걸리지만 배열의 크기가 커질 경우 모두 탐색을 해야 알 수 있다는 점이 단점이라 생각했습니다. 또한, 모든 케이스에서 순차적으로 증가 또는 감소할 때만 저 값이 나온다는 확신이 없었기 때문에 접근 방법을 다르게 생각해봤습니다. 물론 이 방식이 코드도 훨씬 짧고 가독성도 높긴 하지만, 탐색 중간에 mixed임을 알면서도 끝까지 탐색해야 한다는 치명적 단점이 있기 때문에 다른 방식을 선택했습니다. 위에서 먼저 설명한 최종 접근 방식을 정리하면 아래와 같습니다.
* Key point!
1. 주어진 배열의 첫번째 원소가 1인지 8인지 판단
2. 그 다음 배열부터 순차적으로 증가 or 감소하는지 판단
위의 알고리즘 대로라면 처음 구상했던것 보다 훨씬 빠를 것이라 예상합니다. 물론 배열의 크기가 8로 매우 작아 큰 차이는 안보이겠지만 배열의 크기가 매우 커진다면 차이가 조금씩 발생할 것입니다. 그래도 첫 번째 접근했던 방식도 O(n)의 시간 복잡도를 가지기 때문에 눈에 띄게 느려지는 것은 아닙니다. 오늘의 풀이는 여기까지 하고 하단에 소스코드와 출력 결과 사진을 첨부하고 마치도록 하겠습니다.
#include <iostream>
using namespace std;
int main()
{
int note[8]; // 음계를 저장할 변수
for (int i = 0; i < 8; i++)
scanf("%d", ¬e[i]);
if(note[0] == 1){
bool ascending = true;
for(int i = 1;i < 8;i++){
if(note[i] != i + 1){
ascending = false;
break;
}
}
if(ascending)
printf("ascending\n");
else
printf("mixed\n");
} // 첫음계가 1부터 시작할때 ascending인지 판별
else if(note[0] == 8){
bool descending = true;
for(int i = 1;i < 8;i++){
if(note[i] != 8 - i){
descending = false;
break;
}
}
if(descending)
printf("descending\n");
else
printf("mixed\n");
} // 첫음계가 8부터 시작할때 descending인지 판별
else
printf("mixed\n"); // 그 이외의 모든 경우
return 0;
}